2020年の学習振り返り
高校数学や英語の能力不足を痛感していたので、今年はそれらを学習することにした。 万全と勉強しても続かなそうだったのと、自分の能力値を可視化したかったので、いくつか試験を受験した
数学検定2級
- 受験日:2020/8/30
- 結果:合格(初受験)
- 所要時間:410時間

- 数学検定2級の範囲はだいたい高校数学のⅠ,A,Ⅱ,B相当
- 自分は高校数学をサボってしまった(大学受験にも使ってない)ので、復習というよりほぼ初見学習になってしまった(サボってきたことを激しく後悔している)
- 使った教材
- 数検出版の高校数学の教科書(Ⅰ,A,Ⅱ,B)
- 数学のトリセツ Ⅱ・B(動画がわかりやすくて最高)
- 数学関連のyoutube動画(数学系youtuberの方々に感謝)
情報処理安全確保支援士試験
- 受験日:2020/10/18
- 結果:合格(初受験)
- 所要時間: 180時間
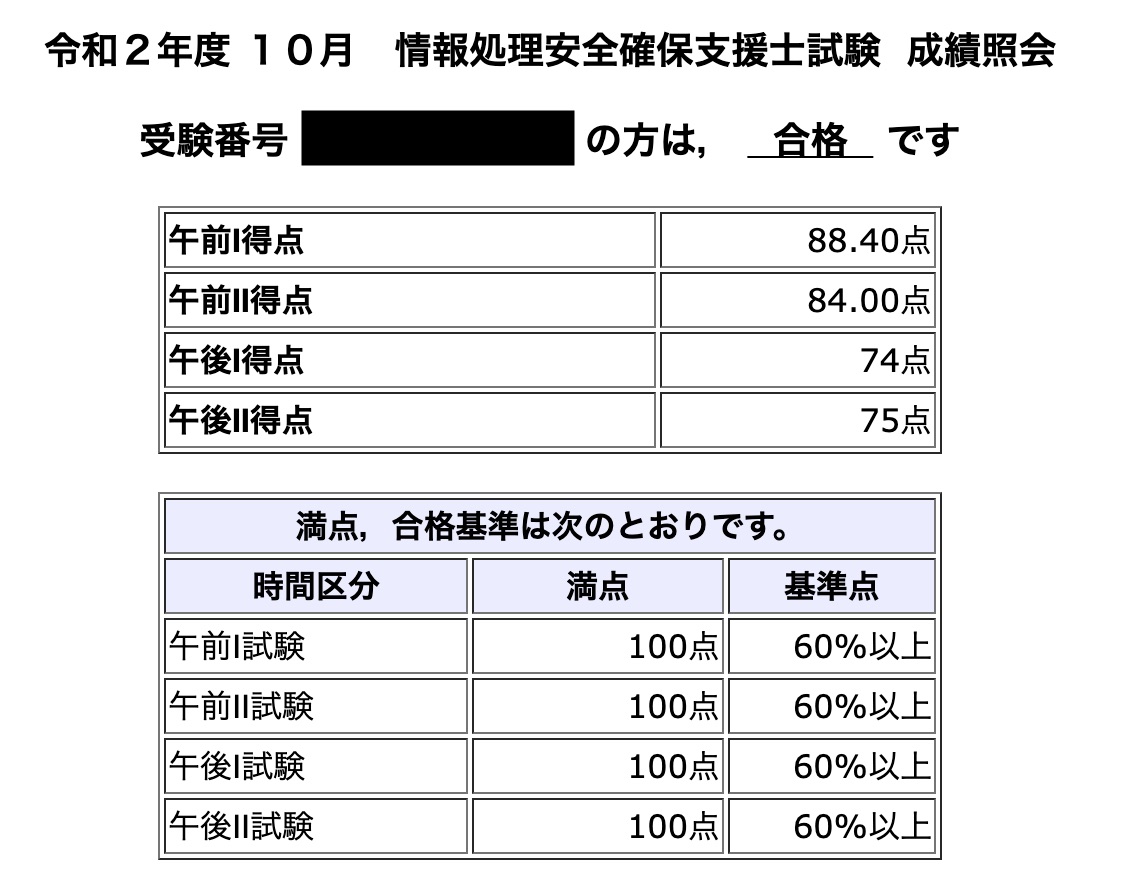
- ざっと頭の中にセキュリティ関連知識のインデックス作るのにとても良かった
- 高度共通の午前1試験範囲に中途半端なビジネス情報(例:PPMの金のなる木)が入ってくるのは不毛に感じた
- 使った教材
TOEIC L & R
- 受験日:2020/12/6
- 結果:900点(前回 10年以上前: 670点)
- 所要時間:130時間

- 10年くらい前に受けた結果がよくなかったので苦手意識あったが、かなり点数あがったので嬉しい
- 金のフレーズ(通称金フレ)という単語帳と、abceedというアプリがとてもよかった
- 使った教材
その他
- 統計の基礎を少し勉強した
- ピアノをはじめた。全キーのメジャースケールとダイアトニックコードは一通り覚えた
感想
- 高校数学を1から独学するのは辛かった
- 英語は10年前と比べると、とても学習環境がよくなってる(youtube, netflixなどの動画コンテンツ最高)
- 継続的に学習すると、徐々にではあるが確実に「分からなかったことが分かるようになる」ので楽しい
来年
- 一日2,3時間の学習は継続する
- 数Ⅲと大学教養レベルの数学・統計を勉強する
- 英語はスピーキングに重点を置きつつ地道に続ける
東大松尾研のDeep Learning基礎講座でチームが優秀賞を受賞しました
東京大学 松尾研究室主催のDeep Learning基礎講座(2018)でチームが口頭発表の優秀賞を受賞しました。(最優秀賞は別チームの方々)

発表タイトルは 「Deep Learningによる一般物体認識を活用した 硬貨カウントの試み」
硬貨を撮影するとその総額をカウントしてくれるアプリをチーム(6名)で作りました
利用シーンは、
- 知らない国の硬貨を手早くカウント
- イベントや文化祭時の集計
- 寺、神社のお賽銭カウント(メンバーの実家がお寺だった)
などを想定しました
- 対象はいったん日本円の硬貨(1円、5円、10円、50円、100円、500円)に限定
- データセットが無かったので自前で約1,000枚分の画像を撮影・アノテーション(アノテーションツールはVoTTを使用)
- データオーギュメンテーションで4,000枚程度に水増し
- モデルはYOLOv3を利用(darknet実装)
- google colabやメンバーのGPUマシンを用いて学習
- precisionとrecallのF値で学習結果を評価
- 学習したモデル(yolov3のモデル)をcoremlのモデルに変換してiphoneアプリに組み込み(Non-Maximum Suppressionはiphoneアプリ側で行う)
のようにして作りました。撮影の状況にによって大きく精度が悪化したり、硬貨が重なってる時どうするのか、一画面に収まりきらない場合にどうするのか、光の強さにどう対応するか、など課題は多くあるものの、デモの完成までもっていけました
日本円をアノテーションしたフリーの学習データは見あたらなかったので、全員で手分けして作成しました。(ひたすら画像にバウンディングボックスをアノテーションしていく作業は心が折れそうになりましたが、作業時間の感覚が掴めたのは良い収穫)
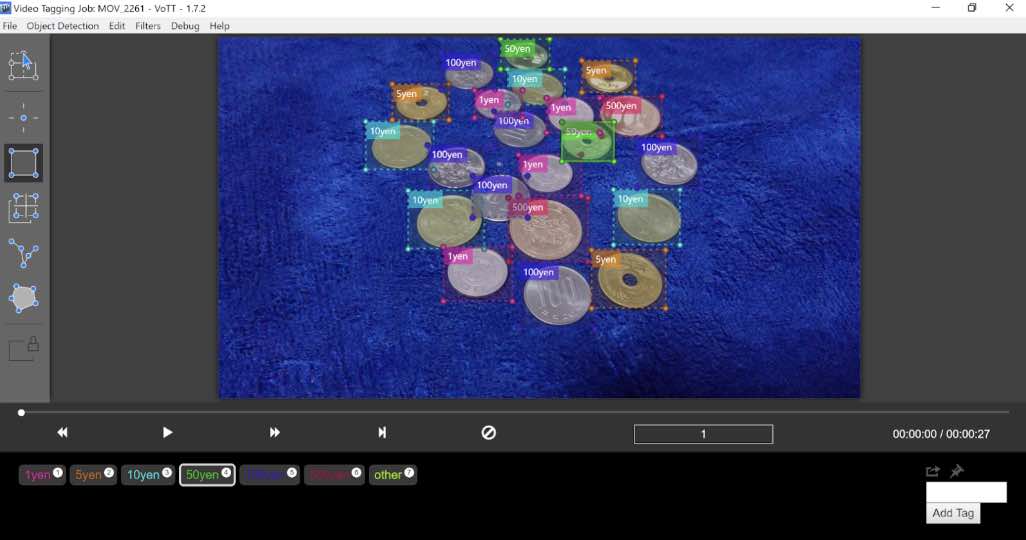
その後の各フェーズ(データ水増し、GPU環境の調達、モデルトレーニング、学習結果の評価、アプリ作成、資料作成など)はメンバーで分担。チーム決定から発表までは約2ヶ月で学生1名・社会人5名というメンバー構成。オンラインMTGがメインでしたが、自発性の高いメンバーにめぐまれたいいチームでした。
私は主にデモアプリ作成を担当。最初webカメラで作ってたのですが、スマホでさくっと動いたら便利だなと思い、iphoneアプリに作り変えました。(yolov2とv3で出力形式が異なったりしてかなり苦戦しました。。)
Deep Learning基礎講座 は講義とプロジェクト合わせて約半年間。講義期間は毎週プログラミングの宿題が出るハードな講義でしたが、松尾研の方々の貴重な講義が聞け、GPU環境が使え、切磋琢磨する受講生の方々と毎週コンペ形式の宿題に挑戦できるという環境は控えめにいって最高でした。
(前半の方の講義で講師の方から「今回が山場です、頑張ってください」と励ましの言葉があり一旦安堵したものの、numpyでシンプルなネットワークをスクラッチで実装する宿題から、CNN、RNN、VAE、GAN、強化学習と山が高くなっていき「いつになったら山場が終わるのかw」と思ったのはいい思い出)
大変貴重な機会を提供してくださった東京大学 松尾研究室のみなさまには本当に感謝です。これからもディープラーニングやっていきです
Vue Fes Japan 2018 Reject Conference (プレイドで開催!)にいってきました #vuefes_reject
Vue.js 日本ユーザーグループ主催のVue Fes Japan 2018 Reject Conferenceにいってきました
スポンサーはPLAIDさん、forkwellさん。会場はPLAIDさんのオフィス。まさかの芝。すごい

Vue Fes Japan 2018には応募枠5に対して40件近くのCFPが届いたらしいです。今回はVue Fesには惜しくも採択されなかったセッションということでしたが、Web components、WebGL、OpenID Connect、BlockChain等、普段あまり触れる機会のないテーマに関する発表が多く、新しい刺激に満ちた会でした。私はVue Fes行けなかったのですが、Reject Conこれてよかったです。
忘れないうちにメモ残しておきます
※ 他の方の参加メモもあがっています https://scrapbox.io/yamanoku/Vue_Fes_Japan_2018_Reject_Conference
Vue.js with Web Components
- Takahiro Saekiさん
- Twitter: https://twitter.com/hirodeath
- GitHub: https://github.com/takahiro-saeki
- Front End Developer
Web Components、使ったことなかったのでイベントのあとちょっと調べた。以下のGoogle Developersの動画がgoogle chartを例に説明していてわかりやすかった。
https://www.youtube.com/watch?v=T5y_lmLngAk
「jsフレームワークによらずhtmlタグとして再利用可能」「jsやcssが独自タグにカプセル化される(グローバルに干渉されない)」といったあたりがポイントか。Web Componentsはユースケースがあまり想像できていなかったのだけど、確かにgoogle chartとかgoogle mapsとかがjsフレームワークによらずhtmlタグのように読み込めたら提供側も使う側も嬉しそう。個人開発や1チーム内で完結する開発をしている限りはあまり使わないかもだが(会場挙手でもWeb Components使っている人あまりいなかった)、「大企業内で異なるjsフレームワークで作られたUIパーツを再利用可能にしたい」といったケースで有効そう。
Vue CLI 3はVue.jsで作ったコンポーネントをWeb Componentsとしてビルドすることができる。Vueすごい。
Create & Publish Web Components With Vue CLI 3 - Vue.js Developers
Identiry Provider Keycloakの紹介と、それを用いたNuxt.jsでのOpenID Connect認証機能の実装
デモアプリ:
- onigraさん
- Twitter: https://twitter.com/onigra_
- GitHub: https://github.com/onigra
- 株式会社エス・エム・エス
Keycloakは知らなかった。なぜfirebase auth使わずにわざわざ自前でKeycloak立てたのかな?と思ったけど社内認証システムをつくるさいに独自要件があり、自分たちで手を入れられるものを作りたかったとのこと。axiosでの認証はaxiosのinterceptorsをつかってやってるらしい。nuxtで一瞬ログイン後の画面がちらつく問題に対する対策(以下)も共有してくれてありがたかった。
https://www.yo1000.com/posts/2018-05-26-nuxt-spa-redirect.html#%E7%8F%BE%E8%B1%A1
個人的にはサーバーサイドKotlin使っているということで親近感。
Vue.js/Nuxt.js で 実現できた PWA の リアルタイム動画ラップ・バトル・アプリ
- lulznekoさん
- Twitter: https://twitter.com/lulzneko
- GitHub: https://github.com/lulzneko
- Riotz
24時間のハッカソンでここまで作るとかすごいできだった。Nuxt.js使うのハッカソンが初めてだったらしいし。。(最初は経験のあるriot.jsでいこうと思ったがハッカソン中にPWA対応の優れていそうなNuxt.jsを発見して使うことに決めたらしい)。Nuxt.jsとサーバーレスの力もあるだろうけど、それにしても早い。
Vue.js×TypeScript×Blockchain Ethereumで作るアプリケーションをはじめからていねいに
- 小堀輝さん
- GitHub: https://github.com/anneau
- 株式会社エイチーム
Blockchain全くわかっていなかったのだけど、タイトルどおりBlockchainについてはじめから丁寧に説明した上でVue.jsのテーマに入ってくれてわかりやすかった。データを従来型のサーバー型で保存するかBlockchain上に保存するかの判断基準として「絶対に改ざんされたくないデータをBlockchain上に保存する」と説明されていたが、改ざんされたくないのはサーバー側に保存するデータも同じなので、「そのBlockchainに参加しているユーザーに対してデータが改ざんされていないことを保証したい」ということなのかな?と思った。
Non-DOM components with WebGL in Vue.js
- 小山田晃浩さん
- Twitter: https://twitter.com/yomotsu
- GitHub: https://github.com/yomotsu
- 株式会社ピクセルグリッド
3D描画のデモを見て、すごい!コードみたい!と思ったらgithubにあげてくれていた。ありがたい。Vue.jsからWebGL扱う方法や、「x,y,zで3つの値をwatchすると、同時に変わると3回renderしちゃう。computedにまとめてそれをwatchしてる」など具体的な実装Tips盛りだくさんで大変参考になった。YouTubeでvue webglで検索したら発表者の方の別のイベントでの動画がヒットした。こちらも参考になる
https://www.youtube.com/watch?v=YJMePm4rJUY
レガシーアプリケーションのリニューアルにNuxt.jsで戦う
私の前職エムスリーで一緒にリニューアルやった鈴木さんによる発表。一緒にインタビューも受けた仲なのだけど、Nuxt.jsの方のプロジェクトは私はあまり関わっておらず、鈴木さんがリードしてくれた。Nuxt.js x TypeScriptのやり方や、components配下の構成管理は今も他のプロジェクトで鈴木さんのやり方を参考にさせてもらっている。特にAPIレスポンスの種類やプロパティが多いプロジェクトにおいて、APIサーバーからswagger-codegenなりでTypeScriptのクライアント自動生成するのはとてもよい。Vue.js x TypeScriptの嬉しみがぐっと強まる。
懇親会
予定あって出れなかったのですが、Vue Beerがデプロイされてました(エムスリーはVue Fes 2018のビールスポンサーさせていただきました)

スタッフのみなさま、お疲れ様でした!スポンサーの方々ありがとうございました!
Kotlin Fest 2018でサーバサイドKotlinのテストについて発表してきた #kotlinfest
昨日8/25(土)に、日本Kotlinユーザグループが運営するKotlin Fest 2018が東京コンファレンスセンター品川にて開催され、同僚の @suusan2go と二人で「How to Test Server-side Kotlin」というタイトルで発表してきました。セッションを聞きにきてくださったみなさん、運営のみなさん、ありがとうございました。

沢山の方が参加するイベントとあって、発表直前までとても緊張していたのですが、随所にスピーカーに対する心遣いが散りばめられており、大変過ごしやすいイベントでした。ここではスピーカーとして感じたことを書いておこうと思います。(私が所属するエムスリーはスポンサーとしても参加したのですが、それはまた会社の方のブログで)
発表資料はこちらです
オープニングセッションでの「盛り上げよう!」
イベントの最初に日本Kotlinユーザグループ代表の長澤太郎さんと藤原聖さんによるオープニングセッションがあったのですが、その中で「スピーカーの方々は参加者のみなさんからのフィードバックを楽しみにしています。ぜひ皆さんで盛り上げましょう!拍手するところでは拍手、おおーというところではおおーと声に出してフィードバックしましょう」といった旨の呼びかけをされてました

このオープニングの呼びかけもあってか、私達の発表の際にも参加者のみなさんから温かいフィードバックをいただくことができました。
ちょっとしたアイスブレイクとして「昨日発表資料を作ってる時、長澤太郎さんの写真をダウンロードしたら、なぜかMacがバグってデスクトップから消えなくなってしまいましたw」というエピソードをお話したのですが、ちゃんと笑っていただけて一安心でした
なんかmacがバグって太郎さんがデスクトップから消えなくなったw pic.twitter.com/pZ7CscUA7H
— まえはりん (@maeharin) 2018年8月24日
自己紹介で「はてなブックマーク1200超えたことが自慢です!」といったら大きな拍手がもらえたことも嬉しかったです(まさかここで拍手してもらえると思ってなかったw)
それと、セッションがはじまる前にフリースペースでお話をした方々が実際にセッションを聞きに来てくださったのがとても嬉しかった。懇親会の時にも話しかけていただけて、こういうフィードバックをいただけるのは本当に発表者冥利につきますね。
発表後の「Ask The Speaker」スペース
発表後にはスピーカーに自由に質問できる「Ask The Speaker」というスペースが用意されており、次のセッションまでの休憩時間に質問できるような仕組みになってました。スピーカーとしては「次のセッションの方の邪魔にならないように早く捌けなきゃなー」など気にしなくてよくなりますし、参加者の方も「そこに行けばスピーカーに質問できる」と明確に分かるので、いい仕組みだなと思いました。質問に来てくださった方々、ありがとうございます!
控室とかTシャツとか
それ以外にも、スピーカー用の控室からセッションのライブビューイングが見れるのが驚きでした。自分の発表がはじまるまで資料の修正をしたりしながら、他のセッションを見ることができるのは細かい配慮だなぁと感心しました。
控室がとても快適なので、最後のしらじさんのセッションもライブビューイングで見ようと思ったのですが、会場で見てください!とご本人から声をかけていただき、会場でみることにしました。当然ながら会場で見たほうが臨場感があってよかったですw(しらじさんのブログで神対応なんて言っていただいてますが、逆に声かけさせてしまってすみません!)
あと、Kotlin Fest 2018のTシャツがもらえました。めっちゃかわいい

Kotlin Fest 2018、楽しかった!
セッション聞きに来てくださったみなさん、ありがとうございます!そして運営のみなさん、本当にお疲れ様でした!
DBスキーマからKotlinのテストフィクスチャを自動生成するgradleプラグインを作った
サーバーサイドKotlinでDB接続テストする際、テストデータのセットアップにはDbSetup が便利です。DbSetupは「xmlなどの外部ファイル」ではなく「コード」でテストフィクスチャを生成できるJavaライブラリで、以下のようなKotlin用のDSLも提供してくれているので重宝しています。
insertInto("users") { mappedValues( "id" to 1, "name" to "前原 秀徳", "job" to "engineer", "status" to "ACTIVE", ... ) }
ただ、これだとカラム数が数十個になってくると記述が面倒だし(仕事だと100カラム近いテーブルもあるんですよね。。)、ちょっとだけ値が異なるパターンを色々作りたい、といった際にしんどいな感じてました。
DBスキーマからコードを自動生成してくれて、かつRubyのfactory_botのような使い心地だったら楽だなと思い、factlinというgradle pluginを作ったので紹介します。
- 既存のDBスキーマを元にKotlinのコードを自動生成する(自動生成されたコードはDbSetupに依存)
- 自動生成されたコードを使うとRubyのfactory_botのような使い心地でテストフィクスチャをセットアップできる
- 自動生成されるコードのテンプレートやデフォルト値はカスタマイズ可能
といった代物です。例えば、postgresでこんなテーブル定義があった場合
CREATE TABLE users ( id SERIAL PRIMARY KEY, name VARCHAR(256) NOT NULL, job VARCHAR(256) NOT NULL DEFAULT 'engineer', status VARCHAR(256) NOT NULL DEFAULT 'ACTIVE', age INTEGER NOT NULL, score NUMERIC NOT NULL, is_admin BOOLEAN NOT NULL, birth_day DATE NOT NULL, nick_name VARCHAR(256), created_timestamp TIMESTAMP WITHOUT TIME ZONE NOT NULL, updated_timestamp TIMESTAMP WITHOUT TIME ZONE ); COMMENT ON TABLE users IS 'user table'; COMMENT ON COLUMN users.id IS 'primary key'; COMMENT ON COLUMN users.name IS 'user name'; COMMENT ON COLUMN users.job IS 'job name'; COMMENT ON COLUMN users.status IS 'activate status'; COMMENT ON COLUMN users.age IS 'user age'; COMMENT ON COLUMN users.score IS 'game score'; COMMENT ON COLUMN users.is_admin IS 'user is admin user or not'; COMMENT ON COLUMN users.birth_day IS 'user birth day'; COMMENT ON COLUMN users.nick_name IS 'nick name';
このプラグインを実行すると、以下のようなKotlinのコードが自動生成されます。
data class UsersFixture ( val id: Int = 0, // primary key val name: String = "", // user name val job: String = "", // job name val status: String = "", // activate status val age: Int = 0, // user age val score: BigDecimal = 0.toBigDecimal(), // game score val is_admin: Boolean = false, // user is admin user or not val birth_day: LocalDate = LocalDate.now(), // user birth day val nick_name: String? = null, // nick name val created_timestamp: LocalDateTime = LocalDateTime.now(), val updated_timestamp: LocalDateTime? = null ) fun DbSetupBuilder.insertUsersFixture(f: UsersFixture) { insertInto("users") { mappedValues( "id" to f.id, "name" to f.name, "job" to f.job, "status" to f.status, "age" to f.age, "score" to f.score, "is_admin" to f.is_admin, "birth_day" to f.birth_day, "nick_name" to f.nick_name, "created_timestamp" to f.created_timestamp, "updated_timestamp" to f.updated_timestamp ) } }
生成されたコードは、
- テストフィクスチャを表すData Class
- DbSetupのinsertIntoメソッドをラップした拡張関数
で構成されてます。1.Data Classの各プロパティには、データベースのカラム型に応じたKotlinの型とデフォルト値が自動生成されます。デフォルト値はnullableなカラムならnull、nullableでない場合はカラムの型に応じた値(数値なら0、文字列なら空文字)といった具合に設定されますが、後述するカスタマイズ設定である程度カスタマイズ可能です。また、DBカラムにコメントがついている場合、コメントもつくようになっています。
上記の自動生成されたコードは、テストの中で以下のように使います。これによりDBにテストデータがinsertされ、そのデータを用いたテストを行うことができます。
dbSetup(dest) {
deleteAllFrom(listOf("users"))
// DBにテストデータをセットアップする
insertUsersFixture(UsersFixture(id = 1, name = "foo"))
insertUsersFixture(UsersFixture(id = 2, name = "bar"))
}.launch()
...DBのデータを使ったテスト
自動生成されたFixtureクラスはData Classになっており、かつカラムの型に沿ったデフォルト値が設定されているので、「ちょっとだけ値が異なるテストフィクスチャ」を簡単に生成することができます。IDEで補完が効いてくれて、定義元にジャンプすればカラムのコメントも確認できて便利です(100個近くカラムがあるテーブルだと特に嬉しい)

フィクスチャのパターンを作る
自動生成されたクラスがData Classになっているという点がポイントで、Data Classのcopyメソッドを使うことで、Rubyのfactory_botのように「フィクスチャのパターンに名前をつけて取り回せるようにしておく」ことが可能です。以下のようにKotlinの拡張関数とcopyを使います。ちなみに、メンテナンスしやすくするため(カラムが変更されコードを再生成する場合に備えて)、自動生成されたFixtureクラスには手を加えず、別のディレクトリとファイルを作って拡張関数を定義するのがオススメです。
fun UsersFixture.default() = this.copy(job = "エンジニア", age = 30) fun UsersFixture.active() = this.default().copy(status = "ACTIVE") fun UsersFixture.inActive() = this.default().copy(status = "IN_ACTIVE")
テストでこんな風に使います
insertUsersFixture(UsersFixture().active().copy(id = 1, name = "テスト1")) insertUsersFixture(UsersFixture().inActive().copy(id = 2, name = "テスト2"))
カスタマイズ
自動生成されるコードはある程度カスタマイズ可能となっています。
| 設定 | 内容 | デフォルト |
|---|---|---|
| fixtureOutputDir | 自動生成されるコードの出力先ディレクトリ | src/test/kotlin/com/maeharin/factlin/fixtures |
| fixturePackageName | 自動生成されるコードのパッケージ名 | com.maeharin.factlin.fixtures |
| fixtureTemplatePath | 自動生成に使うテンプレート(FreeMarker) のパスです | デフォルト |
| exclude table names | 自動生成の対象外にするテーブルリスト | なし |
| includeTables | 自動生成の対象にするテーブルリスト | すべて |
| cleanOutputDir | trueにすると自動生成するまえに出力先ディレクトリを削除します(メンテナンス性のためにtrueにすることを推奨) | false |
| customDefaultValues | 特定のテーブルの特定のカラムのデフォルト値を上書き。形式: [tableName, columnName, defaultValue] | なし |
| customTypeMapper | データベースの型をKotlinの型に変換するルールを上書き。形式: [databaseColumnType, KotlinType] | デフォルトルール |
ぜひ使ってみてください!
この仕組でこれまで1000ケース以上テストケースを書いてきましたが、とくに問題なく快適に使えています。もしよければ、ぜひ使ってみてください!
(宣伝)Kotlin Fest 2018に登壇します
2018年8月25日(土)に東京コンファレンスセンター品川にて開催されるKotlin Fest 2018に登壇します。サーバーサイドKotlinのテストに関して話す予定ですので、ぜひご来場ください!
「どこでもKotlin #1 〜Kotlin実践導入体験談〜」を開催しました #m3kt
8/24(木)に私が所属しているエムスリー主催でKotlinのイベント「どこでもKotlin」を開催しました。エムスリーではAndroid開発言語としてはもちろんのこと、サーバーサイドでもKotlinを実践導入しています。第1回目となる今回は、日本Kotlinユーザグループ代表 長澤太郎をはじめとするエムスリーのKotlinエンジニアが、サーバーサイド、Kotlin/Native、AndroidアプリでKotlinを使った体験談を発表しました。
connpassイベントページ:どこでもKotlin #1 〜Kotlin実践導入体験談〜【増員!】 - connpass

どこでもKotlinについて
ご存知のとおりKotlinはAndroid開発言語として有名です。しかし、その活躍の場はAndroidにかぎらず、サーバーサイド、Nativeなど多岐に渡ります。私は今年Kotlinと出会い、その素晴らしさに惚れ、システムリニューアルにサーバーサイドKotlinを導入することを決めました。Androidだろうとサーバーサイドだろうと、エムスリーだろうとそうでなかろうと、参加者の方と一緒にKotlinを盛り上げていきたいと思い、「どこでもKotlin」というタイトルでイベントを開催することにしました
どこでもKotlinオープニングのスライド。どこでもKotlin使っていきましょ! #m3kt pic.twitter.com/ALjOr1NbGS
— maeharin (@maeharin) 2017年8月27日
#m3kt
ハッシュタグは #m3kt。当日はみなさんに盛り上がっていただき、トレンド入りしました
エムスリー×長澤太郎グッズの数々
#m3kt エムスリー✕たろうグッズが増えてきた pic.twitter.com/nuDsTW2ZMM
— たろう (@ngsw_taro) 2017年8月24日
煽られる参加者の方々
煽られてます #m3kt pic.twitter.com/BZFMapglIt
— monzou (@monzou) 2017年8月24日
発表内容
システムリニューアルと サーバーサイドKotlin
まずは私の発表。システムリニューアルにサーバーサイドKotlinを導入した事例をお話しました
APIサーバーをKotlin x Spring Bootで作成しています(フロントはrailsとvue.js使っています。ここら辺についても機を改めて発表したいと思ってます)

Kotlin ✖︎ Spring Boot サーバーサイドkotlinは怖くない
私と同じチームでドイツ人のルーカスによる発表
サーバーサイドKotlinは怖くない!

Starting Kotlin/Native おなじところ、ちがうところ
後半戦はちょっと怖い?Kotlinの話。エムスリー新卒のエンジニア星川さんによるKotlin/Nativeに関する話

一歩進んだ拡張関数の活用とその濫用で後悔した話
トリはエムスリーのアイドル、長澤太郎による拡張関数の話し

懇親会
最後は懇親会。みなさんKotlinの話題で盛り上がりました
次回「どこでもKotlin #2 〜サーバーサイドKotlin特集〜」は9/28開催!
どこでもKotlinはシリーズ開催します。次回は9/28。テーマは「サーバーサイドKotlin」です! connpassページで募集しますので、是非m3-engineerグループのメンバーに登録ください(twitterの#m3ktでも告知します)
長澤太郎の新刊、サーバーサイドKoltin本が9/29発売!
さらに!9/29に長澤太郎の新刊「Kotlin Webアプリケーション 新しいサーバサイドプログラミング」が発売予定です!(amazonで予約受付中です)

エムスリー love Kotlin!ジョイナス!
エムスリーはKotlinを積極的に導入していきます!カジュアル面談なんかも随時しているので興味がある方は是非下のリンクからご応募ください!全国のKotoliner(ことりにゃ〜)のみなさん、ジョイナス!
have fun Kotlin!

開発合宿行ってきた
いつも一緒に活動してるメンバー5人で、久々に開発合宿してきましたー
今回は「勉強したい技術を使って、何か作ってみる」をテーマとして、1泊2日。場所は伊東の山喜旅館。両日とも会議室を貸し切ることができたので、快適なネット環境の元、集中して開発できました
事前準備
場所と日時を決める
まずはメンバーの都合が合う日程を伝助とかで調整して、その後合宿会場を予約。今回は伊東の山喜旅館にしました。開発合宿では「チェックイン、チェックアウトの時間」が問題になりやすいのですが、山喜旅館は会議室があって1時間1000円くらいで予約できました。チェックインしてない時間は、この会議室を予約することで、開発の時間を多くとれました
旅館のホームページ、いい感じです
テーマ・タイムテーブル決める
今回は「勉強したい技術を使って、何か作ってみる」をテーマにしました。また、タイムテーブルは事前に決めて共有しておくと、当日はかどる。ということで今回はこんな感じにしました。
1日目
| 時間 | 内容 |
|---|---|
| 10:00 - 12:00 | 開発 |
| 12:00 - 13:00 | ランチ |
| 13:00 - 15:00 | 開発 |
| 15:00 - 15:30 | 部屋へ移動 |
| 15:30 - 19:00 | 開発 |
| 19:00 - 20:30 | 夕飯 |
| 20:30 - | フリータイム |
開発時間:7.5h
2日目
| 時間 | 内容 |
|---|---|
| 8:00 - 10:00 | 起床、朝食 、チェックアウト |
| 10:00 - 12:00 | 開発 |
| 12:00 - 13:00 | ランチ |
| 13:00 - 14:00 | 開発 |
| 14:00 - 15:00 | 成果発表! |
| 15:00 - | 解散! |
開発時間:3h
技術調査をしておく
当日開発に集中するために、ある程度技術調査というか勉強はしておく。自分はswiftでiosアプリを作りたかったので、以下のようなことをしておきました
当日の様子








